2 Paradigma Object-Oriented
2.1 Oggetti
Gli oggetti incapsulano uno stato e un comportamento:
Lo stato è identificato dal contenuto di una certa area di memoria.
Il comportamento è definito dai metodi che possono operare sulla rappresentazione dell’area di memoria associata all’oggetto.
Ogni oggetto ha la sua identità, cioè è riconoscibile indipendentemente dal suo stato corrente attraverso un OID univoco immutabile. Cambiare l’OID di un oggetto equivale alla cancellazione dell’oggetto e alla creazione di un altro oggetto con lo stesso stato. Quasi mai il programmatore utilizza esplicitamente i riferimenti. Generalmente questi vengono legati a delle variabili e si fa riferimento agli oggetti mediante gli identificatori di variabile.
2.1.1 Oggetti in UML
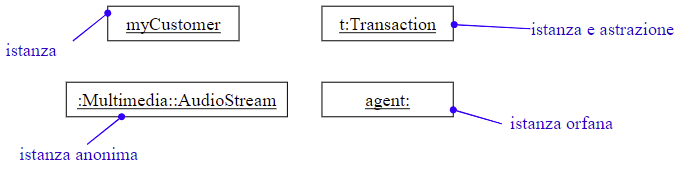
2.2 Classi
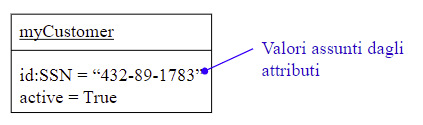
Una classe è la descrizione di una famiglia di oggetti che condividono la stessa struttura (gli attributi) e il medesimo comportamento (operazioni). Nella programmazione OO ogni oggetto è un’istanza di una classe, cioè un oggetto non può essere ottenuto se non si definisce la sua classe di appartenenza.
Idealmente una classe è una realizzazione di un dato astratto. Questo significa che i dettagli della realizzazione sono normalmente nascosti.
Ogni classe ha una doppia componente:
Una componente statica, costituita da campi o attributi, che contengono un valore. I campi caratterizzano lo stato degli oggetti durante l’esecuzione del programma.
Gli attributi si distinguono in base al loro scope:
Attributi d’istanza: sono associati ad una istanza e hanno un tempo di vita pari a quello dell’istanza alla quale sono associati.
Attributi di classe: sono associati alle classi e condivisi da tutte le istanze della classe. Il loro tempo di vita è lo stesso della classe.
Gli attributi di istanza contribuiscono a caratterizzare lo stato di ogni singolo oggetto, mentre gli attributi di classe contribuiscono a definire il fattore comune allo stato di tutti gli oggetti di una classe.
Una componente dinamica, i metodi che manipolano gli attributi, che rappresentano i servizi che possono essere richiesti a un oggetto di una classe.
I metodi possono essere classificati:
Metodi costruttori: sono invocati per istanziare e inizializzare gli oggetti
Metodi di accesso: restituiscono astrazioni significative dello stato di un oggetto
Metodi di trasformazione: modificano lo stato di un oggetto
Metodi distruttori: sono invocati quando si rimuovono gli oggetti dalla memoria
I metodi di accesso e trasformazione possono essere distinti in:
Metodi di istanza: operano su almeno un attributo di istanza, pertanto possono essere invocati solo specificando l’istanza.
Metodi di classe: operano esclusivamente su attributi di classe, pertanto possono essere invocati specificando la classe. Si possono invocare metodi di classe anche quando non è stato creato alcun oggetto per quella classe.
2.2.1 Classi in UML
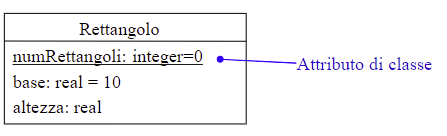
2.2.2 Attributi derivati in UML
Gli attributi derivati sono quelli che possono essere calcolati partendo da altri attributi. UML prevede una rappresentazione specifica mediante una /: 
2.2.3 Stereotipi
Gli stereotipi sono dei tipici meccanismi di estendibilità di UML. Infatti essi estendono il vocabolario di UML, permettendo di creare nuovi blocchi per la costruzione dei modelli.
2.2.4 Visibilità di elementi
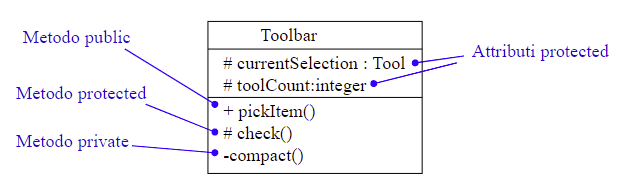
UML consente di specificare i livelli di visibilità di attributi e metodi utilizzando la seguente notazione:
public: l’elemento è preceduto da un +
protected: l’elemento è preceduto da un #
private: l’elemento è preceduto da un –
package: l’elemento è preceduto da un ~
2.2.5 Molteplicità di classe
Per molteplicità di classe si intende il numero di istanze che essa può avere. 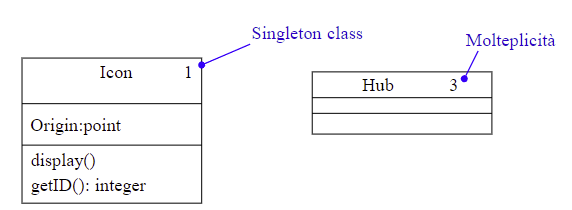
2.2.6 Molteplicità di attributo
È possibile indicare la molteplicità anche per gli attributi, subito dopo il loro nome. 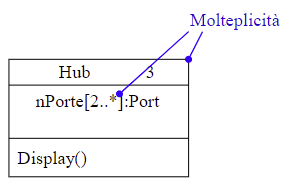
2.2.7 Schema per la definizione di un attributo
[visibilità] nome [molteplicità] [:tipo] [= valore iniziale] [{proprietà}]
In UML esistono tre proprietà predefinite che possono essere utilizzate con gli attributi:
changeable: non vi sono restrizioni sulla modificabilità dell’attributo
addOnly: per gli attributi con molteplicità maggiore di uno, i valori possono essere aggiunti, ma una volta creati, non possono più essere rimossi o modificati
frozen: il valore dell’attributo non può essere modificato dopo che l’oggetto è stato inizializzato
Nel caso in cui la proprietà non viene specificata si sottintende che assume valore changeable.
2.2.8 Schema per la definizione di una operazione
UML distingue tra operazione e metodo:
una operazione è un servizio che può essere richiesto alla classe
un metodo è un’implementazione del servizio
[visibilità] nome [(lista dei parametri)] [: valore di ritorno] [{proprietà}]
Ogni parametro viene scritto nella forma:
[direzione] nome : tipo [ = valore iniziale]
La direzione può assumere uno dei seguenti valori:
in: parametro di input, non può essere modificato
out: parametro di output, può essere modificato per comunicare un’informazione al chiamante
in out: parametro di input che comunque può essere modificato
UML fornisce diverse proprietà predefinite per le operazioni:
isQuery: l’esecuzione dell’operazione lascia lo stato del sistema immutato
leaf: l’operazione non può essere più specializzata nelle sottoclassi
sequential, guarded e concurrent per quanto riguarda la programmazione concorrente
2.2.9 Classi attive
Un oggetto è attivo se esso ha un thread e può far partire un thread concorrente.
Una classe attiva è una classe le cui istanze rappresentano elementi il cui comportamento è concorrente con gli altri.
Essa è mostrata con bordi raddoppiati.

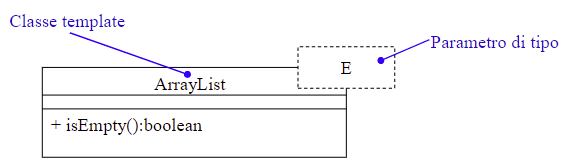
2.2.10 Classi template
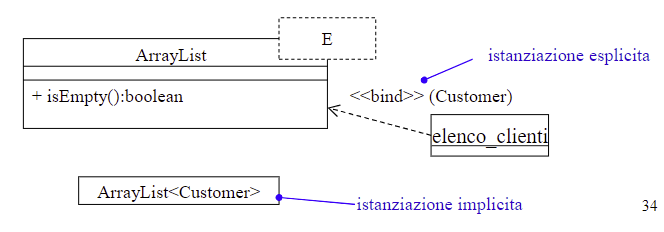
Una classe template definisce una famiglia di classi parametrizzate (con parametro di tipo). Non è possibile usare direttamente una classe template ma è necessario prima specificare il tipo nell’istanziazione.
L’istanziazione di una classe template può essere effettuata in due modi:
Implicitamente, dichiarando una classe il cui nome esplicita i parametri
Esplicitamente, mediante una dipendenza stereotipata bind
2.2.11 Responsabilità delle classi
UML consente di modellare le responsabilità in due modi:
specificandole all’interno della classe
utilizzando delle note
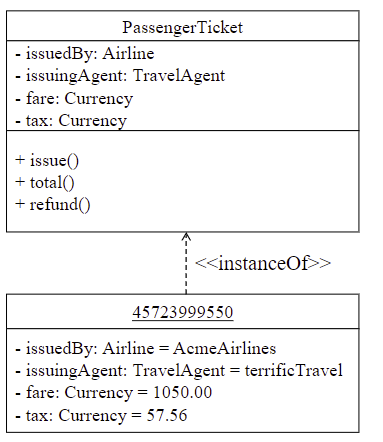
2.2.12 Relazione instance-of
Fra un oggetto e una classe sussiste una relazione ‘instance of’ che specifica che un oggetto è una istanza di una classe. In UML questa relazione è resa con lo stereotipo instanceOf.
2.3 Ereditarietà
Nella progettazione e programmazione OO una relazione fondamentale è quella esistente fra le classi: la relazione di ereditarietà.
Una classe è considerata come un repertorio di conoscenze a partire dal quale è possibile definire altre classi più specifiche.
Una sottoclasse è dunque, una specializzazione della descrizione di una superclasse, della quale essa eredita attributi e metodi.
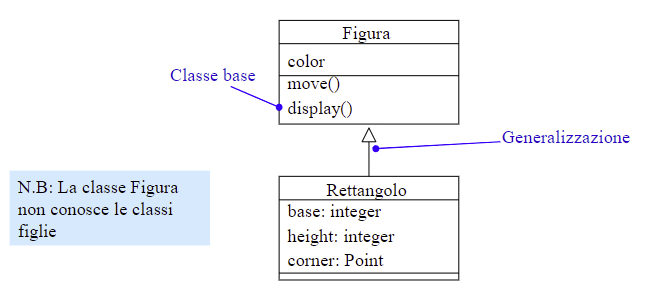
2.3.1 Ereditarietà per estensione
La sottoclasse introduce attributi e metodi non presenti nella superclasse e non applicabili a istanze della superclasse.
La visibilità degli attributi e delle operazioni ereditate dalla superclasse non è modificata.
2.3.2 Ereditarietà per variazione funzionale
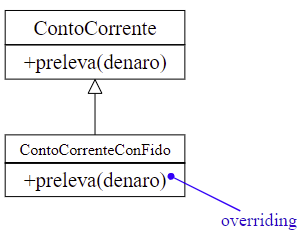
Si ridefiniscono alcune caratteristiche (metodi) della superclasse quando quelle ereditate si rivelano inadeguate per l’insieme di oggetti descritti dalla sottoclasse.
La ridefinizione (overriding) del metodo ereditato riguarda solo l’implementazione e non la segnatura.
Ogni richiesta di esecuzione del metodo ridefinito da parte di un oggetto della sottoclasse, farà riferimento alla nuova implementazione fornita nella sottoclasse.
La visibilità degli attributi e delle operazioni ereditate dalla superclasse non è modificata.
La ridefinizione non è incrementale, quindi i cambiamenti nel metodo originale devono essere riportati anche nei metodi ridefiniti. Purtroppo non c’è alcuna garanzia che questo accada e si possono introdurre degli errori.
2.3.3 Principio di sostituibilità
Data una dichiarazione di una variabile o di un parametro il cui tipo è dichiarato come X, una qualunque istanza di una classe che è discendente di X può essere usato come valore effettivo senza violare la semantica della dichiarazione e il suo uso.
La conseguenza è che una sottoclasse non può rimuovere o rinunciare alle proprietà/metodi della superclasse, altrimenti una istanza della sottoclasse non sarà sostituibile da istanze della superclasse. Pertanto il principio di sostituibilità (o polimorfismo di inclusione) è compatibile con l’ereditarietà per estensione e per variazione funzionale.
Nell’ereditarietà per estensione e per variazione funzionale la relazione di ereditarietà fra classi corrisponde a una relazione di generalizzazione (o “is_a”). Ciò perché ogni istanza di una classe derivata da una classe base va considerata come una istanza della classe base.
2.3.4 Ereditarietà per implementazione
La sottoclasse utilizza il codice della superclasse per implementare l’astrazione associata.
In UML l’ereditarietà di implementazione è indicata utilizzando lo stesso simbolo della generalizzazione, ma specificando a fianco lo stereotipo implementation.
L’ereditarietà di implementazione non è compatibile con il principio di sostituibilità, questo è chiaro seguendo il seguente esempio:
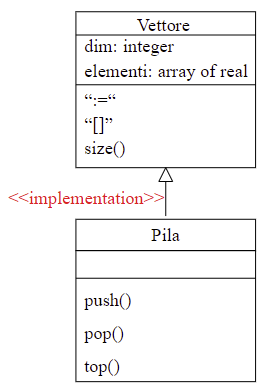
Realizziamo Pila delegandone l’implementazione a Vettore, ovvero le operazioni di Pila possono usare gli operatori di Vettore poichè vengono ereditati, ma la loro visibilità diventa privata, perchè per Pila quelle non sono operazioni lecite.
2.3.5 Proprietà della relazione di generalizzazione
La rappresentazione della relazione di generalizzazione fra un insieme di classi definisce un grafo orientato aciclico.
La relazione di generalizzazione è transitiva e antisimmetrica.
La transitività comporta che le caratteristiche delle classi superiori sono ereditate dalle classi inferiori.
L’antisimmetria definisce una direzione di attraversamento del grafo di ereditarietà che porta dalla sottoclasse alla superclasse.
Poiché un metodo può essere ridefinito in più classi si pone il seguente problema: Sia dato un metodo m, eventualmente ereditato, della classe C1. Da quale classe C2 \in G(C1) si eredita m?
Soluzione:
1° passo: si determina catena di antenati di C1
2° passo: si ricerca la prima occorrenza della (ri-)definizione di m a partire dall’estremità C1 della catena.
2.3.6 Ereditarietà multipla
Una classe può avere più superclassi. In questo caso si parla di ereditarietà multipla.
Anche nell’ereditarietà multipla un metodo può essere ridefinito in diverse classi e si pone lo stesso problema di prima. Consideriamo due casi:
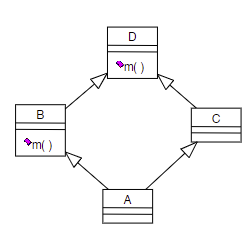
Se C_1 = A c’è un conflitto fra le diverse definizioni di m in B e D. Il conflitto può essere facilmente risolto in questo caso osservando una qualunque linearizzazione del grafo:
A → B → C → D
A → C → B → D
In entrambi i casi, B precede D, il che significa che il metodo m è ereditato da B.
Ora consideriamo questo caso ancora più ambiguo:
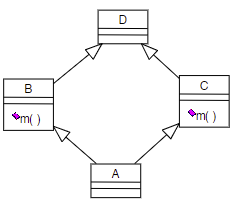
In questo caso le due linearizzazioni non aiutano a scegliere. Esistono dei criteri euristici per gestire queste situazioni conflittuali:
Molteplicità dell’ereditarietà: nel definire che A deriva dalle due superclassi occorrerà elencarle in un qualche ordine, che utilizzeremo per risolvere il conflitto. Questo significa che l’ordine delle classi è utilizzato per preferire una delle due linearizzazioni. Tuttavia questo principio può essere in contraddizione con quello che indica di preferire l’eredità da classi più specifiche.
Modularità: si può scomporre un grafo di ereditarietà in moduli che corrispondono ai diversi punti di vista sull’oggetto. Le linearizzazioni non devono mescolare i diversi sottografi associati ai moduli, quindi non ci sono relazioni di ereditarietà tra classi appartenenti a moduli diversi. Anche in questo caso potrebbero esserci contraddizioni, da risolvere specificando l’ordinamento dei moduli.
2.3.7 Classi astratte
Una classe astratta è una classe non completamente specificata, cioè non è definito il metodo corrispondente a una operazione o più operazioni (il metodo è astratto).
Una classe astratta non può essere istanziata perché il comportamento dei suoi oggetti non sarebbe completamente definito.
Le classi astratte fungono da serbatoi di ereditarietà: non potremo mai creare oggetti a partire da una classe astratta, ma possiamo servircene per dare una radice comune a un insieme di classi che condividono le stesse proprietà e poter quindi sfruttare il polimorfismo di inclusione e il binding dinamico.
2.3.8 Classi finali
Una classe è detta finale quando non può essere ulteriormente specializzata, e quindi non può essere modificata.
Si definisce una classe foglia quando il comportamento della classe dev’essere ben stabilito per ragioni di affidabilità.
2.4 Interfacce
Una interfaccia è la descrizione del comportamento degli oggetti senza specificarne una implementazione. Essa è una collezione di operazioni priva di informazioni sulle implementazioni.
Diversamente da una classe, un’interfaccia non specifica una struttura (non saranno inclusi attributi, se non statici) e non fornisce un’implementazione.
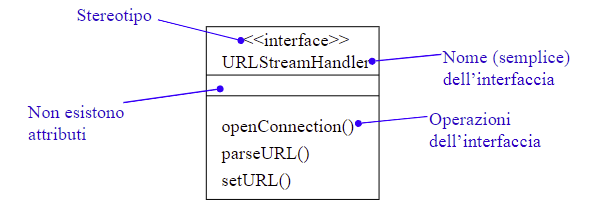
Una o più classi possono realizzare/implementare le operazioni indicate in una interfaccia. La relazione che si stabilisce fra una interfaccia e una classe che la implementa è detta
relazione di realizzazione. In UML è indicata con una freccia tratteggiata.

Le interfacce servono a disaccoppiare la definizione delle operazioni dalla loro implementazione. Per poter usare un certo oggetto è sufficiente conoscere la sua interfaccia: non serve conoscere l’implementazione.
Ad esempio, il metodo sort della classe Arrays necessita solo di sapere che gli elementi dell’array offrono il servizio compareTo. Si crea così una dipendenza di implementazione fra la classe Arrays e l’interfaccia Comparable.

UML permette di rappresentare in modo compatto le due relazioni con questa notazione:

Anche le interfacce possono ereditare da altre interfacce. Poiché non si considerano le implementazioni delle operazioni, l’ereditarietà multipla su interfacce non pone problemi di conflitto di realizzazione. Questo distingue le classi astratte dalle interfacce. Poiché non possono sorgere problemi di conflitto di realizzazione, è permesso a una classe di realizzare più interfacce, per di più non correlate da una relazione di generalizzazione. Infine, più classi possono implementare la stessa interfaccia.
2.5 Aggregazione
Una composizione di oggetti può essere rappresentata permettendo alle variabili di istanza di una classe di puntare a oggetti di altre classi. La relazione che si stabilisce in questo modo fra le classi è detta di aggregazione o composizione (o relazione “has_a”).
Una classe A è in relazione di aggregazione con una classe B quando alcune istanze di B contribuiscono a formare una parte delle istanze di A.
L’aggregazione è, come l’ereditarietà, una relazione asimmetrica.
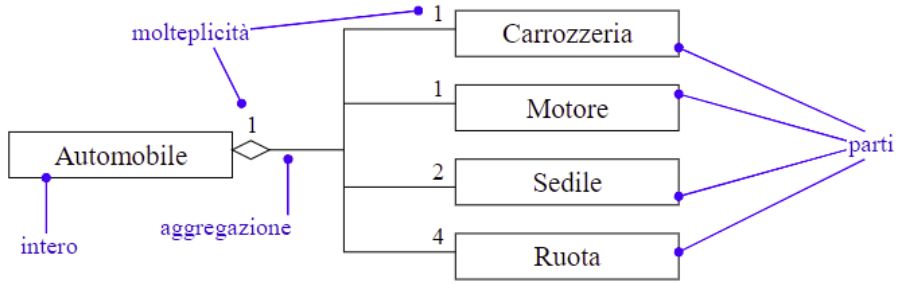
L’aggregazione va usata nei seguenti casi:
Contenimento fisico: la pagina di un libro.
Appartenenza: il giocatore di una squadra di calcio
Composizione funzionale: le ruote di un’automobile.
2.5.1 Aggregazione vs Composizione
Le aggregazioni sono associazioni deboli fra parti e intero. Questo significa che le parti possono esistere senza l’intero.
Un’associazione forte fra parti e intero è detta composizione e si rappresenta in UML mediante un rombo pieno. La composizione comporta una dipendenza esistenziale, in quanto le parti non esistono senza il contenitore. Ciò presuppone che:
Creazione e distruzione delle parti avvengano nel contenitore.
I componenti non siano parti di altri oggetti.
Regola di “non condivisione”: benché una classe possa essere componente di molte altre classi, ogni sua istanza può essere componente di un solo oggetto. Questa regola è caratterizzante della composizione.
La composizione fra classi stabilita in fase di progettazione offre delle informazioni importanti al programmatore che andrà a implementare le classi. In Java il componente sarà privato e non ci sarà alcun metodo che restituisce il suo riferimento.
Il meccanismo di aggregazione/composizione è generalmente usato quando si vogliono utilizzare i servizi di una classe predefinita ma non la sua interfaccia.
L’ereditarietà di implementazione, qualora non dovesse essere permessa da un linguaggio di programmazione, potrebbe essere resa da una relazione di aggregazione/composizione.
2.5.2 Raggruppare classi
I package sono un meccanismo generale per organizzare le classi in gruppi.  Un package definisce un namespace per i suoi elementi. Il nome completo della classe sarà ottenuto indicando prima il nome del package che la contiene mediante la notazione ::
Un package definisce un namespace per i suoi elementi. Il nome completo della classe sarà ottenuto indicando prima il nome del package che la contiene mediante la notazione ::
Elementi della stessa specie, inseriti all’interno di uno stesso package, devono avere necessariamente nomi differenti.
Per evitare la necessità di utilizzare nomi qualificati, un package può importare gli elementi di un altro package nel proprio namespace. Un elemento nel package che importa
può quindi riferirsi a un elemento importato come se esso fosse definito localmente. Se c’è conflitto di nomi in due elementi importati, nessuno dei due elementi è aggiunto al namespace.
Se il nome di un elemento importato è in conflitto con il nome di un elemento definito internamente a un package, il nome dell’elemento interno ha precedenza sul nome importato che non viene aggiunto al namespace.
I package possono essere innestati senza alcun limite di profondità. Un package innestato ha accesso a tutti gli elementi contenuti direttamente nei package esterni, senza necessità di importazione.
2.5.3 Classi interne
Una classe interna è una classe la cui dichiarazione si trova all’interno di un’altra classe ospite.
La inner class puó accedere a tutti i metodi e i campi della classe ospitante, mentre la classe ospitante può vedere solo la parte pubblica della inner class.
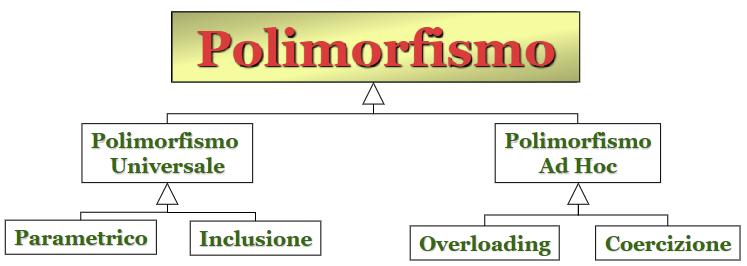
3 Polimorfismo
| Universale | Ad hoc |
|---|---|
| Il polimorfismo è su un numero potenzialmente illimitato di tipi. | Il polimorfismo è su un numero finito di tipi |
| I diversi morfismi sono generati automaticamente. | I diversi morfismi sono generati in modo manuale o semi-manuale |
| C’è una base unificante, comune a tutti i diversi morfismi. | Non c’è una base comune a tutti i morfismi, l’uniformità è un caso e non la regola |
3.1 Polimorfismo ad hoc: Coercizione
La coercizione è il meccanismo di conversione implicita operata da un compilatore per
applicare un operatore definito per oggetti di tipo T_1 anche a oggetti di tipo T_2. Un esempio di coercizione è dato dall’autoboxing e l’unboxing in Java.
Le coercizioni possono essere stabilite staticamente, inserendole automaticamente fra gli argomenti e le funzioni a compile-time, oppure potrebbero essere determinate dinamicamente a run-time.
La coercizione è la forma di polimorfismo più semplice: essa opera a un livello semantico, cioè cambiando la rappresentazione del dato.
3.2 Polimorfismo ad hoc: Overloading
Si ha polimorfismo per overloading quando si usa lo stesso identificatore per metodi differenti e si ricorre a informazioni di contesto per decidere quale metodo è denotato da una particolare occorrenza dell’identificatore.
La disambiguazione necessaria per una corretta compilazione si basa sul tipo degli argomenti del metodo o sulla classe dell’oggetto a cui si richiede il servizio. Possiamo immaginare che una precompilazione del programma potrebbe disambiguare ed eliminare l’overloading dando nomi differenti a metodi differenti. L’overloading è presente nella maggior parte dei linguaggi dove gli operatori aritmetici sono applicabili a più di un tipo.
3.3 Polimorfismo universale: Polimorfismo parametrico
Nel polimorfismo parametrico, una funzione polimorfa ha un parametro di tipo esplicito o implicito, che determina il tipo dell’argomento per ciascuna applicazione della funzione.
Le funzioni che esibiscono il polimorfismo parametrico sono anche dette funzioni generiche e lavorano su argomenti di molti tipi esibendo lo stesso comportamento.
Le funzioni generic dell’Ada sono un esempio di funzioni generiche. Si osservi che il polimorfismo parametrico di Ada/C++ è sintattico, dal momento che una istanziazione generica è effettuata al momento della compilazione sulla base dei tipi effettivi che devono essere determinabili al compile-time.
Rispetto al polimorfismo parametrico propriamente inteso, esse hanno il vantaggio che si può generare del codice ottimizzato per forme di input differenti.
Al contrario, nei veri sistemi polimorfici, il codice è generato solo una volta per ogni procedura generica, come in Java.
3.4 Polimorfismo universale: Polimorfismo di inclusione
Nella programmazione orientata a oggetti, si ha polimorfismo per inclusione se un oggetto appartiene a una classe e a tutte le sue superclassi.
Esso si manifesta in almeno due modi:
Si può assegnare un oggetto di una qualsiasi sottoclasse di una classe C a una variabile definita di classe C
Una funzione che opera su un oggetto di classe C può essere applicata anche a oggetti di classe C^{'}, sottoclasse di C.
L’utilizzo più interessante si ha quando le invocazioni dei metodi su oggetti di classi gerarchicamente correlate producono un comportamento differente, anche se la definizione della funzione è unica.
Ciò dipende dal tipo di legame statico/dinamico fra identificatore di funzione e relativa realizzazione.
Nella maggior parte dei linguaggi di programmazione la visibilità degli identificatori, e dei legami dei nomi alle dichiarazioni, è determinata a compile-time. Si parla di ambito d’azione statico.
Nell’ambito d’azione dinamico (dynamic scope), il legame fra l’uso di un identificatore e la sua
dichiarazione dipende dall’ordine di esecuzione, e così è differito a run-time.
Java ha la tipizzazione statica e il legame dinamico è la regola, non l’eccezione. Solo nei metodi final/static il legame nome di funzione – sua realizzazione diventa statico.
Esempio: si consideri il seguente programma Pascal:
program dynamic(input,output);
var x: integer;
procedure A
begin
write(x);
end; {A}
procedure B
var x: real;
begin
A;
end; {B}
begin
B;
A;
end {dynamic}Poiché il Pascal adotta la regola dell’ambito statico, l’uso della variabile x in A è legato alla variabile intera x nel programma principale. Questo permette di tradurre la write(x) semplicemente in una chiamata a una funzione di libreria di I/O per la scrittura degli interi.
Tuttavia se il legame nome-dichiarazione fosse dinamico, l’uso di x in A sarebbe vincolato alla dichiarazione di x più recente. Pertanto, quando la procedura A è chiamata dalla procedura B, l’uso di x in A viene vincolato alla dichiarazione della variabile reale x nella procedura B, mentre quando A è chiamata direttamente, l’uso di x sarebbe vincolato alla dichiarazione della variabile intera x nel programma principale.
Con un dynamic-binding, la traduzione della chiamata della write(x) può essere determinata solo al run-time.
Questo non vuol dire che il controllo di tipo non possa essere effettuato, ma solo che viene ritardato al momento dell’esecuzione, quando è noto il tipo al quale x è vincolato.
Con lo static-binding, inoltre, il legame dei nomi ai tipi è anch’esso fissato al momento della compilazione.